Database Per Service Design Patterns
Usually, a monolith application has a single big data store that stores the data for all the needs of the application. In microservices, we divide the application into independent services. The database per service pattern suggests having independent, scalable and isolated databases for each microservice instead of having a common datastore. Each service should independently access its own DB, services cannot access each other’s DBs directly.
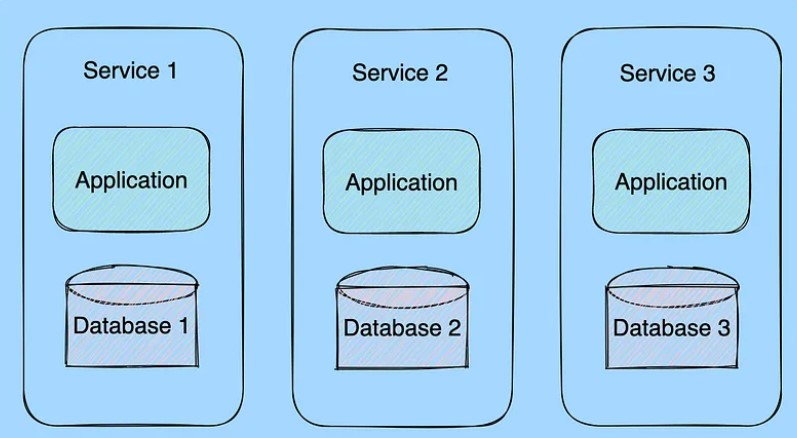
This pattern ensures loose coupling between services, any issues, or changes in one service would not affect any other service or its database. Also, it is not necessary to use a single type of DB for all services. Each service can choose its database according to its requirements.
Example Scenario
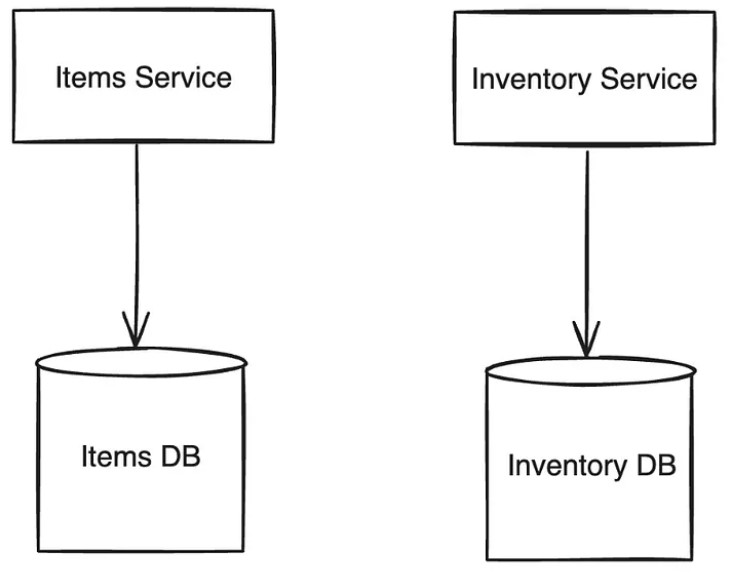
Let us take examples of some of the most common services that any e-commerce platform requires. The typical Orders flow is handled by multiple services. Two services that the order management system interacts with are item service and inventory service. Item service needs data related to items, their cost, sellers selling it, and inventory service needs data related to how much inventory is left for the items. Both data storage requirements are related, but if we store them in a single database, it will become huge, complex, difficult to manage and the queries (especially joins) will take a lot of time to execute.
To solve this problem, we can use the database per service pattern. An items database will store items data and another inventory database will store inventory data. Items service will connect to items db and inventory service will connect to inventory db. This way, if there is any issue in items service, inventory service will still keep running.
How to run queries that require data from more than one service?
One fundamental problem to solve here is what happens if reading data from both items and inventory databases is required. For example, if I need the item name along with inventory numbers for all sellers selling that item? In this case, usually we would perform a join if there was a single database and two tables in it.
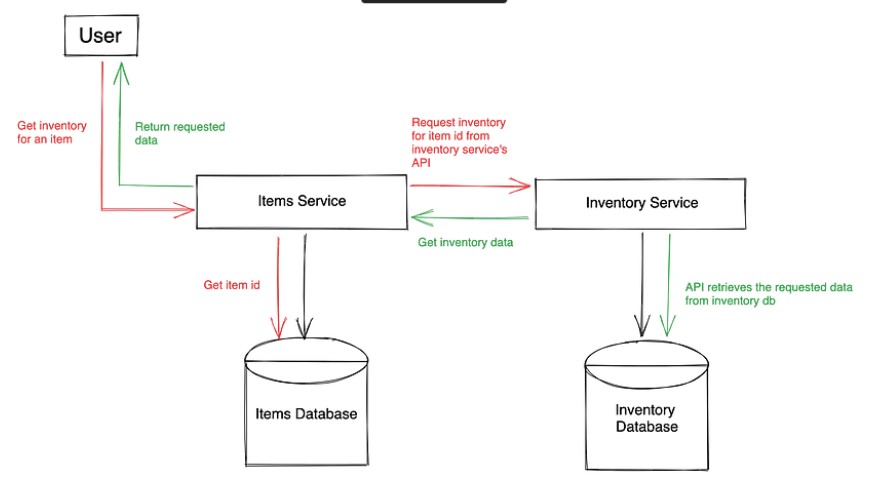
The applications can perform the join instead of the database performing the join. If the items service requires data from inventory service, it can request. The inventory service will have APIs to provide this data. For example, for inventory for a specific item, the item name can be retrieved from the items db, and then using the item id, an API request can be sent to inventory service to get the inventory for that item id. This is known as API composition. One of the ways of achieving this is by using the Saga pattern, as explained further below.
Advantages Over Single Shared Database
You get the following benefits by using the database per service pattern for designing your microservices.
- Faster development — There is no development time coupling between services; each service can be developed independently. For example, if a developer working on items service wants to update the schema of its db, they can do so. The schema of inventory service would not be affected, thus development on inventory service can continue without interference.
- No runtime interference — Any queries on one database will not affect other services. If a query on orders service is taking time to run, queries on inventory service can still execute. Or if inventory service puts a lock on any data item in its database, data in the other databases is not locked.
- Freedom to choose different databases — A single database may not be suited for all microservices. If one service requires a relational database and another service requires a NoSQL database, they are free to choose. In the case of shared database, a single type of db has to be used by all the services, but database per service pattern gives the independence for services to use the database type they require for their use case.
- Fault Tolerance — If orders service database fails, inventory service will still be operational. Database per service pattern gives more fault tolerance than shared database pattern.
- Loose coupling — Changes in one database will not affect the other databases. In case of a shared database, suppose if the orders data has to be moved from one type of db to another type, the whole database needs to be moved. In the case of database per service, only the orders data can be moved independently.
When not to use Database per Service
While it is immensely helpful to use this pattern in large sets of microservices, it is not advisable in the following scenarios:
- In a transaction-heavy system, it might become difficult to use multiple databases. A single RDBMS system is best suited for such use cases. For example, implementation of a banking application where multiple services can do transactions, such as customer service and account manager service should be done using a shared database design to maintain reliability of the transactions.
- Queries that require complex joining of multiple tables might be difficult to implement in this pattern. For example, services that require complex searching use cases where data needs to be derived using joins.